
Abstract
Germinal centres (GC) are lymphoid structures in which B cells acquire affinity-enhancing somatic hypermutations (SHM), with surviving clones differentiating into memory B cells (MBCs) and long-lived bone marrow plasma cells1,2,3,4,5 (BMPCs). SARS-CoV-2 mRNA vaccination induces a persistent GC response that lasts for at least six months in humans6,7,8. The fate of responding GC B cells as well as the functional consequences of such persistence remain unknown. Here, we detected SARS-CoV-2 spike protein-specific MBCs in 42 individuals who had received two doses of the SARS-CoV-2 mRNA vaccine BNT162b2 six month earlier. Spike-specific IgG-secreting BMPCs were detected in 9 out of 11 participants. Using a combined approach of sequencing the B cell receptors of responding blood plasmablasts and MBCs, lymph node GC B cells and plasma cells and BMPCs from eight individuals and expression of the corresponding monoclonal antibodies, we tracked the evolution of 1,540 spike-specific B cell clones. On average, early blood spike-specific plasmablasts exhibited the lowest SHM frequencies. By contrast, SHM frequencies of spike-specific GC B cells increased by 3.5-fold within six months after vaccination. Spike-specific MBCs and BMPCs accumulated high levels of SHM, which corresponded with enhanced anti-spike antibody avidity in blood and enhanced affinity as well as neutralization capacity of BMPC-derived monoclonal antibodies. We report how the notable persistence of the GC reaction induced by SARS-CoV-2 mRNA vaccination in humans culminates in affinity-matured long-term antibody responses that potently neutralize the virus.
Similar content being viewed by others
Main
Vaccination of humans with the Pfizer-BioNTech SARS-CoV-2 mRNA vaccine BNT162b2 induces a robust but transient circulating plasmablast response and a persistent germinal centre (GC) reaction in the draining lymph nodes6. Whether these persistent GC responses lead to the generation of affinity-matured memory B cells (MBCs) and long-lived bone marrow-resident plasma cells (BMPCs) remains unclear. To address this question, we analysed long-term B cell responses in the participants enrolled in our previously described observational study of 43 healthy participants (13 with a history of SARS-CoV-2 infection) who received two doses of BNT162b26,7 (Extended Data Tables 1). Long-term blood samples (n = 42) and fine needle aspirates (FNAs) of the draining axillary lymph nodes (n = 15) were collected 29 weeks after vaccination (Fig. 1a). Bone marrow aspirates were collected 29 (n = 11) and 40 weeks (n = 2) after vaccination, with the 40-week time point used only for B cell receptor (BCR) repertoire profiling (Fig. 1a). None of the participants who contributed FNA or bone marrow specimens had a history of SARS-CoV-2 infection.

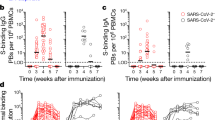
a, Forty-three participants (13 with a history of SARS-CoV-2 infection) were enrolled, followed by vaccination. Blood (n = 42) was collected before and at indicated time points after vaccination. For 15 participants without infection history, aspirates of draining axillary lymph nodes were collected at indicated time points after vaccination. For 11 participants without infection history, aspirates of bone marrow were collected at 29 and 40 weeks after vaccination. b, Representative flow cytometry plots of GC B cells (CD19+CD3−IgDlowBCL6+CD38int) and S-binding GC B cells in lymph nodes 29 weeks after vaccination. The percentage of cells in the bound region is indicated. c, Kinetics of total (left) and S-binding GC B cells (right) as gated in b. d, Representative ELISpot wells coated with the indicated antigens, bovine serum albumin or anti-immunoglobulin and developed in blue (IgG) and red (IgA) after plating the indicated numbers of BMPCs. e, Frequencies of IgG-secreting BMPCs specific for the indicated antigens 29 weeks after vaccination. Symbols at each time point represent one sample in c (n = 15) and e (n = 11). f, Plasma anti-S IgG titres measured by ELISA in participants without (red, n = 29) and with (black, n = 9) infection history. Horizontal lines and numbers indicate geometric means. Results are from one experiment performed in duplicate. g, Representative flow cytometry plot of S-binding MBCs (CD20+CD38−IgDlowCD19+CD3−) in blood 29 weeks after vaccination. h, Frequencies of S-specific MBCs in participants without (red, n = 29) and with (black, n = 13) infection history as gated in g. Horizontal lines indicate medians in e and h. LoD, limit of detection.
GC B cells were detected in FNAs from all 15 participants (Fig. 1b, c, left, Extended Data Fig. 1a, Extended Data Table 2). All 14 participants with FNAs collected prior to week 29 generated spike (S)-binding GC B cell responses of varying magnitudes (Fig 1b, c, right, Extended Data Table 2). Notably, S-binding GC B cells were detected in FNAs from 10 out of 15 participants at week 29 (Fig. 1b, c, right, Extended Data Table 2), demonstrating that two-thirds of the sampled participants maintained an antigen-specific GC B cell response for at least six months after vaccination. S-binding lymph node plasma cells (LNPCs) were also detected in FNAs from all 15 participants and exhibited similar dynamics to S-binding GC B cells, albeit at lower frequencies within the total B cell population (Extended Data Fig. 1a, b, Extended Data Table 2). None of the FNAs demonstrated significant contamination with peripheral blood, based on the nearly complete absence of myeloid cells (Extended Data Table 2).
Frequencies of BMPCs secreting IgG or IgA antibodies against either the 2019–2020 inactivated influenza virus vaccine, the tetanus–diphtheria vaccine or S protein were assessed in bone marrow aspirates collected 29 weeks after vaccination by enzyme-linked immunosorbent spot assay (ELISpot) (Fig. 1d, e, Extended Data Fig. 1c). Influenza and tetanus–diphtheria vaccine-specific IgG-secreting BMPCs were detectable (median frequencies of 1.4% and 0.15%, respectively) in all 11 participants (Fig. 1e). S-binding IgG-secreting BMPCs were detected in 9 out of 11 participants (median frequency of 0.06%). IgA-secreting BMPCs specific to influenza vaccine were detected in 10 out of 11 participants, but IgA-secreting BMPCs directed against the tetanus–diphtheria vaccine and the S protein were largely below the limit of detection (Extended Data Fig. 1c). All participants had detectable plasma anti-S IgG antibodies and circulating S-binding MBCs at the 29-week time point (Fig. 1f–h). Anti-S IgG titres at 29 weeks were higher than titres observed in a cohort of unvaccinated people who had recovered from SARS-CoV-2 measured 29 weeks after infection9,10,11 (Extended Data Fig. 1d). Vaccinated participants with a history of SARS-CoV-2 infection had significantly higher titres of anti-S IgG antibodies at 5 and 29 weeks compared with their naive counterparts9,11,12 (Fig. 1f). Similar trends were observed for plasma anti-S IgM and IgA antibodies (Extended Data Fig. 1e). S-binding MBCs were detected in all participants, with a median frequency of 0.23% of total circulating B cells (Fig. 1g, h, Extended Data Fig. 1f).
To track S-specific B cell evolution and clonal distribution within blood, lymph node and bone marrow, we performed single-cell RNA sequencing (scRNA-seq) and concurrent BCR sequencing of immune cells from eight participants who contributed specimens from the three compartments. We first sorted plasmablasts from samples collected at their peak frequencies, one week after the second immunization6 (Fig. 2a, top, Extended Data Fig. 2a). We then investigated the dynamics of the immune response in draining axillary lymph nodes. Single-cell transcriptional analysis of lymph nodes revealed distinct immune cell populations, as previously described13,14,15,16 (Fig. 2a, bottom left, Extended Data Fig. 2b, c, Extended Data Table 3). To further distinguish distinct B cell subsets in the lymph node, we performed unbiased secondary clustering of the B cell populations from the total cellular analysis (Fig. 2a, bottom right, Extended Data Fig. 2d, e, Extended Data Table 3). Around 40% and 7.9% of the B cells in the lymph node had GC B cell and LNPC transcriptomic profiles, respectively.

a, Uniform manifold approximation and projection (UMAP) showing scRNA-seq transcriptional clusters of total cells (left) and of B cells (right) from plasmablasts (PBs) sorted from PBMC (top) and from FNA of lymph nodes (bottom). Each dot represents a cell, coloured by phenotype as defined by transcriptomic profile. Total numbers of cells are at the top right corner. FDC, follicular dendritic cell; GC, GC B cell; Mo, monocyte; NK, natural killer cell; PB, plasmablast; pDC, plasmacytoid dendritic cell. b, Positive binding of recombinant monoclonal antibodies derived from GC B cells (blue) or LNPCs (green) to SARS-CoV-2 S measured by ELISA. Results are from one experiment performed in duplicate.
We next generated recombinant monoclonal antibodies from expanded clones detected in FNA samples 7 and 15 weeks after vaccination, representing early and late time points. For two of the eight participants from whom the late point was unavailable due to insufficient specimens, we analysed two separate early time points: weeks five and seven for participant 02a, and weeks four and seven for participant 04. A total of 2,099 recombinant monoclonal antibodies were generated, of which 1,503 (71.6%) bound SARS-CoV-2 S in an enzyme-linked immunosorbent assay (ELISA) (Fig. 2b, Extended Data Table 4). In subsequent analyses, we included 37 previously identified S-binding monoclonal antibodies generated from GC B cells at week 4 from participants 07, 20, and 226. Clonal relationships were computationally inferred using heavy chains from scRNA-seq BCR libraries (Extended Data Table 5), bulk-seq BCR libraries for GC B cells, LNPCs (Extended Data Fig. 2g) and BMPCs (Extended Data Table 5), as well as previously published bulk-seq BCR libraries of sorted plasmablasts and GC B cells6, and magnetically enriched IgDlow activated B cells or MBCs from PBMC17. B cell clones with experimentally validated S-binding B cells were designated S-binding clones (Extended Data Fig. 2f) and accounted for 43.1% and 64.4%, respectively of the single-cell profiled GC B cells and LNPCs (Extended Data Fig. 2h, Extended Data Table 3). B cells that were clonally related to S-binding B cells were also found in the plasmablast compartment in blood (6.7%) and the MBC compartment in lymph nodes (0.3%) (Extended Data Fig. 2h, Extended Data Table 3).
B cell maturation in the germinal centre
We analysed the proportion of S-binding GC B cells clonally related to week 4 circulating plasmablasts. The frequencies of plasmablast-related, S-binding GC B cells varied broadly among participants, ranging from 12.7% to 82.5% (Fig. 3a). Consistent with our flow cytometry results (Fig. 1c), GC B cells from long-lasting S-binding clones were observed for at least 29 weeks after vaccination (Extended Data Fig. 3a). In addition, we detected the presence of clonally related MBCs in blood at 29 weeks after vaccination (Extended Data Fig. 3b). S-binding GC B cells accumulated significantly higher levels of SHM compared to clonally related plasmablasts, and this difference increased over time (Fig. 3b). We observed a 3.5-fold increase in SHM frequency among all S-binding GC B cells between weeks 4 and 29 (Fig. 3c, Extended Data Fig. 3c). S-binding MBCs detected at 29 weeks after vaccination, however, had slightly lower SHM frequencies than their clonally related GC B cell counterparts (Extended Data Fig. 3d). The relative proportion of S-binding GC B cells expressing BCR of IgA isotype increased in the lymph node over time (Extended Data Fig. 3e). Clonal analysis revealed a high degree of overlap between S-binding GC and LNPC compartments (Fig. 3d). Furthermore, SHM frequencies of both S-binding LNPCs and GC B cells increased over time at a very similar rate with small differences (Fig. 3e) in contrast to those between S-binding plasmablast and GC B cells (Fig. 3b).

a, Circos diagrams showing clonal overlap between S-binding plasmablasts and GC B cells at indicated time points. Purple and grey chords correspond to clones spanning both compartments and clones spanning only the GC compartment, respectively. Percentages are of GC B cell clones related to plasmablasts at each time point. b, Nucleotide mutation frequency in the immunoglobulin heavy chain variable gene (IGHV) region for clonally related week-4 plasmablasts and GC B cells at weeks 4 (n = 81), 5 (n = 52), 7 (n = 289), 15 (n = 162) and 29 (n = 47). c, IGHV nucleotide mutation frequency of S-binding GC B cells at weeks 4 (n = 1,701), 5 (n = 21,543), 7 (n = 62,927), 15 (n = 49,837) and 29 (n = 3,314). Horizontal lines and numbers represent medians. P values were determined by Kruskal–Wallis test followed by Dunn’s multiple comparison test. d, Circos diagrams showing clonal overlap (purple) between S-binding GC B cells and LNPCs over combined time points. Percentages are of GC B cell clones overlapping with LNPCs or vice versa. Arc length corresponds to the number of BCR sequences and chord width corresponds to clone size in a and d. e, IGHV nucleotide mutation frequency of clonally related GC B cells and LNPCs at weeks 4 (n = 48), 5 (n = 224), 7 (n = 877), 15 (n = 449) and 29 (n = 76). Each dot represents the median SHM frequency of a clone within the indicated compartment, and medians are presented on the top of each dataset in b and e. P values were determined by paired two-sided Mann–Whitney test and corrected for multiple testing using the Benjamini–Hochberg method in b and e. ****P < 0.0001.
Affinity maturation of antibody response
To determine whether the increase in SHM frequencies of S-specific GC B cells and LNPCs over time is reflected in increased circulating anti-S antibody binding affinity, we measured the avidity of plasma anti-S IgG. In participants without a history of SARS-CoV-2 infection, anti-S IgG avidity increased at 29 weeks compared with the 5-week time point. Of note, participants with a history of SARS-CoV-2 infection had similar plasma anti-S IgG avidity at 5 and 29 weeks after vaccination (Fig. 4a). Consistently, SHM frequencies of S-binding LNPCs increased over time (Fig. 4b). S-binding BMPCs from 29 and 40 weeks after vaccination exhibited a degree of SHM that was similar to that of LNPCs from 15 and 29 weeks after vaccination (Fig. 4b) and significantly higher than any other S-binding B cell population except for MBCs (Extended Data Fig. 4a). To understand the evolutionary trajectory of vaccine-induced B cell lineages, we analysed S-specific clones using a phylogenetic model tailored for BCR repertoires18. Consistent with their SHM frequencies (Fig. 4b), plasmablasts tended to locate closer to the germline on the phylogenetic trees, whereas LNPCs and BMPCs tended to be evolutionarily more distant (Fig. 4c, Extended Data Fig. 4b). In contrast to plasmablasts, which clustered to a separate branch of their own, BMPCs and LNPCs co-located on shared branches, suggesting a closer evolutionary relationship between BMPCs and LNPCs (Fig. 4c). Together, these results support a model in which S-specific BMPCs are the products of affinity-matured, GC-derived LNPCs.

a, Avidity indices of plasma anti-S IgG between the indicated time points in participants without (red, n = 29) and with (black, n = 9) a history of SARS-CoV-2 infection. b, IGHV nucleotide mutation frequency of S-binding plasmablasts (n = 2,735), LNPCs at weeks 4 (n = 552), 5 (n = 11,253), 7 (n = 45,436), 15 (n = 24,538) and 29 (n = 571), and BMPCs (n = 47). Horizontal lines and numbers represent median values. P values were determined by Kruskal–Wallis test followed by Dunn’s multiple comparison test. c, Representative phylogenetic trees showing inferred evolutionary relationships between plasmablasts, LNPCs and BMPCs. Horizontal branch length represents the expected number of substitutions per codon in V-region genes, corresponding to the scale bar. Clone IDs are displayed near the root of the trees. Asterisks denote neutralizing monoclonal antibodies. d, Neutralizing activity of clonally related plasmablast- and BMPC-derived monoclonal antibodies (n = 8) against SARS-CoV-2 D614G strain. Dotted line indicates detection limit. Results are from one experiment with duplicates in a and d. e, Equilibrium dissociation constant (KD) of neutralizing clone-derived Fabs (n = 8) interacting with immobilized S protein measured by BLI. Symbols indicate KD values of clonally related, plasmablast (red)- and BMPC (black)-derived Fabs. Results are from at least two replicates in e. P values were determined by two-tailed Wilcoxon matched-pairs signed rank test in a, d and e. NS, P > 0.9999, ****P < 0.0001.
We next expressed monoclonal antibodies derived from clonally related plasmablasts and BMPCs and their corresponding monomeric antigen-binding fragments (Fabs) (Extended Data Table 6). We then examined binding affinity and in vitro neutralization capacity using biolayer interferometry (BLI) and high-throughput GFP-reduction neutralization test19, respectively. BMPC-derived Fabs exhibited significantly higher binding affinity against S protein compared with plasmablast-derived Fabs (Extended Data Fig. 4c, d). Of the 21 S-specific clones we detected among BMPCs, 7 potently neutralized the SARS-CoV-2 D614G strain (Extended Data Fig. 4e). These BMPC-derived monoclonal antibodies showed higher neutralizing potency than their clonally related, plasmablast-derived counterparts (Fig. 4d), consistent with the significantly increased binding affinity of the BMPC-derived Fabs to S protein (Fig. 4e). Overall, the increased frequency of SHM observed over time and the correlated functional improvements in neutralization suggest that the GC reactions induced by SARS-CoV-2 mRNA vaccination facilitate the development of affinity-matured BMPCs.
Discussion
This study evaluated whether the persistent GC response induced by SARS-CoV-2 mRNA-based vaccines in humans6 results in the generation of affinity-matured MBCs and BMPCs1,3,13,20,21. The two-dose series of BNT162b2 induced a robust S-binding GC B cell response that lasted for at least 29 weeks after vaccination. The results of such persistent GC reactions were evident in the form of circulating S-binding MBCs in all participants and S-specific BMPCs 29 weeks after vaccination in all but two of the sampled participants. It is likely that S-specific BMPCs in those two participants are present but below the assay detection limit. Longitudinal tracking of more than 1,500 vaccine-induced B cell clones revealed the gradual accumulation of SHM and isotype switching to IgA within the GC B cell compartment. We also show that GC B cells differentiate into affinity-matured LNPCs within the lymph node, with some of these cells potentially migrating to the bone marrow where they establish long-term residence. The enhanced maturity of the secreted antibodies was reflected in the significantly increased avidity of circulating anti-S IgG antibodies over time. It is also evident from increased affinity of BMPC-derived monoclonal antibodies detected six months after vaccination in comparison to that of their corresponding plasmablast-derived monoclonal antibodies. Our data corroborate multiple reports demonstrating the maturation of circulating MBC responses after SARS-CoV-2 mRNA vaccination in humans9,10,12,22,23,24.
This study shows that a persistent vaccine-induced GC response in humans culminates in the induction of affinity-matured, antigen-specific BMPCs. Notably, none of the 11 bone marrow specimens came from a participant with a history of SARS-CoV-2 infection. An intriguing finding in our study is that the S-specific BMPCs detected more than six months after vaccination exhibited high SHM frequencies relative to other B cell compartments. These data corroborate similar observations made in the mouse model25,26. The mouse data led to the proposal that there is a division of labour between MBCs and long-lived BMPCs27,28. In that model, BMPCs secrete highly specific, high-affinity antibodies that provide the first layer of protection against the invading pathogen upon re-exposure, whereas MBCs would only be engaged in the event that the pathogen is not fully neutralized by BMPC-derived antibodies. Consistent with this notion, multiple reports have documented the evolution of circulating MBCs induced by SARS-CoV-2 mRNA vaccination in humans9,10,12,23. These reports have shown that not only did the frequency of circulating S-binding MBCs increased over time, but their ability to recognize S proteins from emerging SARS-CoV-2 variants seems to have expanded as well22,23. These data indicate an important role for affinity maturation of responding B cell clones beyond increasing binding affinity to the immunizing antigen.
Our study raises a number of important questions that will need to be addressed in future studies concerning the effects of an additional homologous or heterologous immunization on the dynamics and products of ongoing GCs, particularly with respect to breadth of induced B cell responses. It also remains to be addressed whether the IgA+ GC B cell compartment induced by this systemic immunization can give rise to long-term IgA+ MBCs and BMPCs. Overall, our data demonstrate the remarkable capacity of mRNA-based vaccines to induce robust and persistent GC reactions that culminate in affinity-matured MBC and BMPC populations.
Methods
Sample collection, preparation and storage
All studies were approved by the Institutional Review Board of Washington University in St Louis. Written consent was obtained from all participants. Forty-three healthy volunteers were enrolled, of whom 13 had a history of confirmed SARS-CoV-2 infection (Extended Data Table 1). Fifteen out of 43 healthy participants provided FNAs of draining axillary lymph nodes. In 6 out of the 15 participants, a second draining lymph node was identified and sampled following secondary immunization. One participant (15) received the boost vaccination in the contralateral arm; draining lymph nodes were identified and sampled on both sides. Eleven out of 43 healthy participants provided bone marrow aspirates. Forty-eight participants who had recovered from mild SARS-CoV-2 infection but had not been vaccinated within 7 months of illness were previously described21.
Peripheral blood samples were collected in EDTA tubes, and PBMCs were enriched by density gradient centrifugation over Ficoll-Paque PLUS (Cytiva) or Lymphopure (BioLegend). The residual red blood cells were lysed with ammonium chloride lysis buffer, and cells were immediately used or cryopreserved in 10% dimethyl sulfoxide in fetal bovine serum (FBS).
Ultrasound-guided FNA of draining axillary lymph nodes was performed by a radiologist or a qualified physician’s assistant under the supervision of a radiologist. Scans were performed with a commercially available ultrasound unit (Loqic E10, General Electric) using an L2–9 linear array transducer with transmit frequencies of 7, 8, and 9 MHz or a L6–15 linear array transducer with transmit frequencies of 10, 12, and 15 MHz. Lymph node dimensions and cortical thickness were measured, and the presence and degree of cortical vascularity and location of the lymph node relative to the axillary vein were determined before each FNA. For each FNA sample, six passes were made under continuous real-time ultrasound guidance using 25-gauge needles, each of which was flushed with 3 ml of RPMI 1640 supplemented with 10% FBS and100 U ml−1 penicillin-streptomycin, followed by three 1-ml rinses. Red blood cells were lysed with ammonium chloride buffer (Lonza), washed with washing buffer (phosphate-buffered saline supplemented with 2% FBS and 2 mM EDTA), and immediately used or cryopreserved in 10% dimethyl sulfoxide in FBS. Participants reported no adverse effects from phlebotomies or serial FNAs.
Bone marrow aspirates of approximately 30 ml were collected in EDTA tubes from the iliac crest. Bone marrow mononuclear cells (BMMCs) were enriched by density gradient centrifugation over Ficoll-Paque PLUS, and then the remaining red blood cells were lysed with ammonium chloride buffer (Lonza) and washed with washing buffer. BMPCs were enriched from BMMCs using EasySep Human CD138 Positive Selection Kit II (StemCell Technologies) and immediately used for ELISpot or cryopreserved in 10% dimethyl sulfoxide in FBS.
Antigens
Recombinant soluble S protein derived from SARS-CoV-2 was expressed as previously described29. In brief, a mammalian cell codon-optimized nucleotide sequences coding for the soluble version of S (GenBank: MN908947.3, amino acids 1–1213) including a C-terminal thrombin cleavage site, T4 fold trimerization domain and hexahistidine tag was cloned into the mammalian expression vector pCAGGS. The S protein sequence was modified to remove the polybasic cleavage site (RRAR to A) and two stabilizing mutations were introduced (K986P and V987P, wild-type numbering). Recombinant proteins were produced in Expi293F cells (Thermo Fisher Scientific) by transfection with purified plasmid using the ExpiFectamine 293 Transfection Kit (Thermo Fisher Scientific). Supernatants from transfected cells were collected 3 days after transfection, and recombinant proteins were purified using Ni-NTA agarose (Thermo Fisher Scientific), then buffer-exchanged into PBS and concentrated using Amicon Ultra centrifugal filters (MilliporeSigma). For flow cytometry staining, recombinant S was labeled with Alexa Fluor 7647-NHS ester or biotinylated using the EZ-Link Micro NHS-PEG4-Biotinylation Kit (Thermo Fisher Scientific); excess Alexa Fluor 647 and biotin were removed using 7-kDa Zeba desalting columns (Thermo Fisher Scientific).
For expression of biotinylated SARS-CoV-2 S Avitag, the CDS of pCAGGS vector containing recombinant soluble SARS-CoV-2 S protein was modified to encode 3′ Avitag insert after the 6×His tag (5′-His tag-GGCTCCGGGCTGAACGACATCTTCGAAGCCCAGAAGATTGA GTGGCATGAG-Stop-3′; HHHHHHGSGLNDIFEAQKIEWHE-) using inverse PCR mutagenesis in a method described previously30. Protein expression and purification of SARS-CoV-2 S-Avitag was performed using the same methods as above. Immediately, after purification, site-specific biotinylation was performed similar to Avidity recommendations. Specifically, SARS-CoV-2 S-Avitag substrate was at 40 μM concentration with 15 μg ml−1 BirA enzyme in a 0.05 M bicine buffer at pH 8.3 containing 10 mM ATP, 10 mM MgOAc and 50 μM biotin, and the reaction was performed for 30 °C for 1 h. The protein was then concentrated and buffer exchanged with PBS using a 100-kDa Amicon Ultra centrifugal filter (MilliporeSigma).
Flow cytometry and cell sorting
Staining for flow cytometry analysis and sorting was performed using freshly isolated or cryo-preserved PBMCs or FNAs. For FNA staining, cells were incubated for 30 min on ice with biotinylated and Alexa Fluor 647-conjugated recombinant soluble S and PD-1-BB515 (EH12.1, BD Horizon, 1:100) in 2% FBS and 2 mM EDTA in PBS (P2), washed twice, then stained for 30 min on ice with IgG-BV480 (goat polyclonal, Jackson ImmunoResearch, 1:100), IgA-FITC (M24A, Millipore, 1:500), CD45-A532 (HI30, Thermo, 1:50), CD38-BB700 (HIT2, BD Horizon, 1:500), CD20-Pacific Blue (2H7, 1:400), CD27-BV510 (O323, 1:50), CD8-BV570 (RPA-T8, 1:200), IgM-BV605 (MHM-88, 1:100), HLA-DR-BV650 (L243, 1:100), CD19-BV750 (HIB19, 1:100), CXCR5-PE-Dazzle 594 (J252D4, 1:50), IgD-PE-Cy5 (IA6-2, 1:200), CD14-PerCP (HCD14, 1:50), CD71-PE-Cy7 (CY1G4, 1:400), CD4-Spark685 (SK3, 1:200), streptavidin-APC-Fire750, CD3-APC-Fire810 (SK7, 1:50) and Zombie NIR (all BioLegend) diluted in Brilliant Staining buffer (BD Horizon). Cells were washed twice with P2, fixed for 1 h at 25 °C using the True Nuclear fixation kit (BioLegend), washed twice with True Nuclear Permeabilization/Wash buffer, stained with FOXP3-BV421 (206D, BioLegend, 1:15), Ki-67-BV711 (Ki-67, BioLegend, 1:200), T-bet-BV785 (4B10, BioLegend, 1:400), BCL6-PE (K112-91, BD Pharmingen, 1:25), and BLIMP1-A700 (646702, R&D, 1:50) for 1 h at 25 °C, washed twice with True Nuclear Permeabilization/Wash buffer and resuspended in P2 for acquisition. For memory B cell staining, PBMC were incubated for 30 min on ice with biotinylated and Alexa Fluor 647-conjugated recombinant soluble S in P2, washed twice, then stained for 30 min on ice with IgG-BV480 (goat polyclonal, Jackson ImmunoResearch, 1:100), IgD-Super Bright 702 (IA6-2, Thermo, 1:50), IgA-FITC (M24A, Millipore, 1:500), CD45-A532 (HI30, Thermo, 1:50), CD38-BB700 (HIT2, BD Horizon, 1:500), CD24-BV421 (ML5, 1:100), CD20-Pacific Blue (2H7, 1:400), CD27-BV510 (O323, 1:50), CD8-BV570 (RPA-T8, 1:200), IgM-BV605 (MHM-88, 1:100), CD19-BV750 (HIB19, 1:100), FcRL5-PE (509f6, 1:100), CXCR5-PE-Dazzle 594 (J252D4, 1:50), CD14-PerCP (HCD14, 1:50), CD71-PE-Cy7 (CY1G4, 1:400), CD4-Spark685 (SK3, 1:200), streptavidin-APC-Fire750, CD3-APC-Fire810 (SK7, 1:50) and Zombie NIR (all BioLegend) diluted in Brilliant Staining buffer (BD Horizon). Cells were washed twice with P2 and resuspended in P2 for acquisition. All samples were acquired on an Aurora using SpectroFlo v.2.2 (Cytek). Flow cytometry data were analysed using FlowJo v.10 (BD Biosciences).
For sorting plasmablasts from peripheral blood, B cells were enriched from PBMC by first using EasySep Human Pan-B cell Enrichment Kit (StemCell Technologies), and then stained with CD20-PB (2H7, 1:400), CD3-FITC (HIT3a, 1:200), IgD-PerCP-Cy5.5 (IA6-2, 1:200), CD71-PE (CY1G4, 1:400), CD38-PE-Cy7 (HIT2, 1:200), CD19-APC (HIB19, 1:200) and Zombie Aqua (all BioLegend). For sorting GC B cells and LNPCs from the lymph node, single-cell suspensions were stained for 30min on ice with PD-1-BB515 (EH12.1, BD Horizon, 1:100), CD20-Pacific Blue (2H7, 1:100), IgD-PerCP-Cy5.5 (IA6-2, 1:200), CD19-PE (HIB19, 1:200), CXCR5-PE-Dazzle 594 (J252D4, 1:50), CD38-PE-Cy7 (HIT2, 1:200), CD4-Alexa-Fluor-700 (SK3, 1:400), CD71-APC (CY1G4, 1:100), and Zombie Aqua (all BioLegend). Cells were washed twice, and single plasmablasts (live singlet CD19+CD3−IgDlowCD38+CD20−CD71+), GC B cells (live singlet CD19+CD4−IgDlowCD71+CD38intCD20+CXCR5+), LNPCs (live singlet CD19+CD4−IgDlowCD38+CD20−CD71+) were sorted using a FACSAria II.
ELISA
Assays were performed in MaxiSorp 96-well plates (Thermo Fisher) coated with 100 μl of recombinant SARS-CoV-2 S, Donkey anti-human IgG (H+L) antibody (Jackson ImmunoResearch, 709-005-149) or BSA diluted to 1 μg ml−1 in PBS, and plates were incubated at 4 °C overnight. Plates then were blocked with 10% FBS and 0.05% Tween 20 in PBS. Plasma or purified monoclonal antibodies were serially diluted in blocking buffer and added to the plates. Monoclonal antibodies and plasma samples were tested at 10 μg ml−1 and 1:30 starting dilution, respectively, followed by 7 additional threefold serial dilutions. Plates were incubated for 90 min at room temperature and then washed 3 times with 0.05% Tween 20 in PBS. Secondary antibodies were diluted in blocking buffer before adding to wells and incubating for 60 min at room temperature. Horseradish peroxidase (HRP)-conjugated goat anti-human IgG (H+L) antibody (Jackson ImmunoResearch, 109-035-088, 1:2,500) was used to detect monoclonal antibodies. HRP-conjugated goat anti-Human IgG Fcγ fragment (Jackson ImmunoResearch, 109-035-190, 1:1,500), HRP-conjugated goat anti-human serum IgA α chain (Jackson ImmunoResearch, 109-035-011, 1:2,500), and HRP-conjugated goat anti-human IgM (Caltag, H15007, 1:4,000) were used to detect plasma antibodies. Plates were washed three times with PBST and three times with PBS before the addition of O-phenylenediamine dihydrochloride peroxidase substrate (MilliporeSigma). Reactions were stopped by the addition of 1 M hydrochloric acid. Optical density measurements were taken at 490 nm. The threshold of positivity for recombinant monoclonal antibodies was set as two times the optical density of background binding to BSA at the highest concentration of each monoclonal antibody. The area under the curve for each monoclonal antibody and half-maximal binding dilution for each plasma sample were calculated using GraphPad Prism v.9. Plasma antibody avidity was measured as previously described31. Areas under the curve were calculated by setting the mean + 3 × s.d. of background binding to BSA as a baseline. In brief, plasma dilutions that would give an optical density reading of 2.5 were calculated from the serial dilution ELISA. S-coated plates were incubated with this plasma dilution as above and then washed one time for 5 min with either PBS or 8 M urea in PBS, followed by 3 washes with PBST and developed as above. The avidity index was calculated for each sample as the optical density ratio of the urea-washed to PBS-washed wells.
ELISpot
ELISpot plates were coated overnight at 4 °C with Flucelvax Quadrivalent 2019/2020 seasonal influenza virus vaccine (Seqirus, 1:100), tetanus/diphtheria vaccine (Grifols, 1:20), SARS-CoV-2 S (10 μg ml−1), anti-human Ig (Cellular Technology) and BSA. A direct ex vivo ELISpot assay was performed to determine the number of total, vaccine-binding or recombinant S-binding IgG- and IgA-secreting cells present in PBMCs or enriched BMPCs using Human IgA/IgG double-colour ELISpot kits (Cellular Technology) according to the manufacturer’s protocol. ELISpot plates were analysed using an ELISpot analyser (Cellular Technology).
Single-cell RNA-seq library preparation and sequencing
Sorted plasmablasts and whole FNA from each time point were processed using the following 10x Genomics kits: Chromium Next GEM Single Cell 5′ Kit v2 (PN-1000263); Chromium Next GEM Chip K Single Cell Kit (PN-1000286); BCR Amplification Kit (PN-1000253); Dual Index Kit TT Set A (PN-1000215). Chromium Single Cell 5′ Gene Expression Dual Index libraries and Chromium Single Cell V(D)J Dual Index libraries were prepared according to manufacturer’s instructions without modifications. Both gene expression and V(D)J libraries were sequenced on a Novaseq S4 (Illumina), targeting a median sequencing depth of 50,000 and 5,000 read pairs per cell, respectively.
Bulk BCR sequencing
Sorted GC B cells and LNPCs from FNA, enriched BMPCs from bone marrow or enriched MBCs from PBMCs from blood were used for library preparation for bulk BCR sequecning. Circulating MBCs were magnetically isolated by first staining with IgD-PE and MojoSort anti-PE Nanobeads (BioLegend), and then processing with the EasySep Human B Cell Isolation Kit (StemCell Technologies) to negatively enrich IgDlo B cells. RNA was prepared from each sample using the RNeasy Plus Micro kit (Qiagen). Libraries were prepared using the NEBNext Immune Sequencing Kit for Human (New England Biolabs) according to the manufacturer’s instructions without modifications. High-throughput 2 × 300-bp paired-end sequencing was performed on the Illumina MiSeq platform with a 30% PhiX spike-in according to manufacturer’s recommendations, except for performing 325 cycles for read 1 and 275 cycles for read 2.
Preprocessing of bulk sequencing BCR reads
Preprocessing of demultiplexed pair-end reads were performed using pRESTO v.0.6.232 as previously described6, with the exception that sequencing errors were corrected using the unique molecular identifiers (UMIs) as they were without additional clustering (Extended Data Table 5). Previously preprocessed unique consensus sequences from reported samples6 were included as they were. Previously preprocessed unique consensus sequences from reported samples17 corresponding to participants 01, 02a, 04, 07, 10, 13, 20, and 22 were subset to those with at least two contributing reads and included.
Preprocessing of 10x Genomics single-cell BCR reads
Demultiplexed pair-end FASTQ reads were preprocessed using the ‘cellranger vdj’ command from 10x Genomics’ Cell Ranger v.6.0.1 for alignment against the GRCh38 human reference v.5.0.0 (‘refdata-cellranger-vdj-GRCh38-alts-ensembl-5.0.0’). The resultant ‘filtered_contig.fasta’ files were used as preprocessed single-cell BCR reads (Extended Data Table 5).
V(D)J gene annotation and genotyping
Initial germline V(D)J gene annotation was performed on the preprocessed BCRs using IgBLAST v.1.17.133 with the deduplicated version of IMGT/V-QUEST reference directory release 202113-234. IgBLAST output was parsed using MakeDb.py from Change-O v.1.0.235. For the single-cell BCRs, isotype annotation was pulled from the ‘c_call’ column in the ‘filtered_contig_annotations.csv’ files outputted by Cell Ranger.
For both bulk and single-cell BCRs, sequence-level quality control was performed, requiring each sequence to have non-empty V and J gene annotations; exhibit chain consistency in all annotations; bear fewer than 10 non-informative (non-A/T/G/C, such as N or -) positions; and carry a non-empty CDR3 with no N and a nucleotide length that is a multiple of 3. For single-cell BCRs, cell-level quality control was also performed, requiring each cell to have either exactly one heavy chain and at least one light chain, or at least one heavy chain and exactly one light chain. Within a cell, for the chain type with more than one sequence, the most abundant sequence in terms of UMI count (when tied, the sequence that appeared earlier in the file) was kept. Ultimately, exactly one heavy chain and one light chain per cell were kept. Additionally, quality control against cross-sample contamination was performed by examining the extent, if any, of pairwise overlapping between samples in terms of BCRs with both identical UMIs and identical non-UMI nucleotide sequences.
Individualized genotypes were inferred based on sequences that passed all quality control using TIgGER v.1.0.036 and used to finalize V(D)J annotations. Sequences annotated as non-productively rearranged by IgBLAST were removed from further analysis.
Clonal lineage inference
B cell clonal lineages were inferred on a by-individual basis based on productively rearranged sequences using hierarchical clustering with single linkage37. When combining both bulk and single-cell BCRs, heavy chain-based clonal inference was performed38. First, heavy chain sequences were partitioned based on common V and J gene annotations and CDR3 lengths using the groupGenes function from Alakazam v1.1.035. Within each partition, heavy chain sequences with CDR3s that were within 0.15 normalized Hamming distance from each other were clustered as clones using the hclust function from fastcluster v1.2.339. When using only single-cell BCRs, clonal inference was performed based on paired heavy and light chains. First, paired heavy and light chains were partitioned based on common V and J gene annotations and CDR3 lengths. Within each partition, pairs whose heavy chain CDR3s were within 0.15 normalized Hamming distance from each other were clustered as clones.
Following clonal inference, full-length clonal consensus germline sequences were reconstructed using CreateGermlines.py from Change-O v.1.0.235 for each clone with the D-segment (for heavy chains) and the N/P regions masked with Ns, resolving any ambiguous gene assignments by majority rule. Within each clone, duplicate IMGT-aligned V(D)J sequences from bulk sequencing were collapsed using the collapseDuplicates function from Alakazam v1.1.035 except for duplicates derived from different time points, tissues, B cell compartments, or isotypes.
BCR analysis
BCR analysis was performed in R v.4.1.0 with visualization performed using base R, ggplot2 v.3.3.540, and GraphPad Prism v.9.
For the B cell compartment label, gene expression-based cluster annotation was used for single-cell BCRs; FACS-based sorting was used in general for bulk BCRs, except that plasmablast sorts from lymph nodes were labelled LNPCs, week 5 IgDlo sorts from blood were labelled activated, and week 7 IgDlo sorts from blood were labelled memory. For the time point label, one blood plasmablast sample that pooled collections in both week 4 and week 5 was treated as week 4; and one blood memory sort sample that pooled collections in both week 29 and week 30 was treated as week 29. For analysis involving the memory compartment, the memory sequences were restricted to bulk-sequenced week 29 memory sorts from blood.
A heavy chain-based B cell clone was considered a S-specific clone if the clone contained any sequence corresponding to a recombinant monoclonal antibody that was synthesized based on the single-cell BCRs and that tested positive for S-binding.
Clonal overlap between B cell compartments was visualized using circlize v.0.4.1341.
SHM frequency was calculated for each heavy chain sequence by counting the number of nucleotide mismatches from the germline sequence in the variable segment leading up to the CDR3, while excluding the first 18 positions that could be error-prone due to the primers used for generating the monoclonal antibody sequences. Calculation was performed using the calcObservedMutations function from SHazaM v.1.0.235.
Phylogenetic trees for S-specific clones containing BMPCs were constructed on a by-participant basis using IgPhyML v1.1.318 with the HLP19 model42. Only heavy chain sequences from week 4 plasmablast compartment, the GC B cell, LNPC and MBC compartments up to and including week 15, and the week 29 or 40 BMPC compartment were considered. For clones with > 100 sequences, subsampling was applied with probabilities proportional to the proportions of sequences from different compartments, in addition to keeping all sequences corresponding to synthesized monoclonal antibodies and all BMPC sequences. Only subsampled sequences from the plasmablast, LNPC and BMPC compartments were used for eventual tree-building. Trees were visualized using ggtree v3.0.443.
Human housekeeping genes
A list of human housekeeping genes was compiled from the 20 most stably expressed genes across 52 tissues and cell types in the Housekeeping and Reference Transcript (HRT) Atlas v.1.044; 11 highly uniform and strongly expressed genes reported45; and some of the most commonly used housekeeping genes46. The final list includes 34 genes: ACTB, TLE5 (also known as AES), AP2M1, BSG, C1orf43, CD59, CHMP2A, CSNK2B, EDF1, EEF2, EMC7, GABARAP, GAPDH, GPI, GUSB, HNRNPA2B1, HPRT1, HSP90AB1, MLF2, MRFAP1, PCBP1, PFDN5, PSAP, PSMB2, PSMB4, RAB11B, RAB1B, RAB7A, REEP5, RHOA, SNRPD3, UBC, VCP and VPS29.
Processing of 10x Genomics single-cell 5′ gene expression data
Demultiplexed pair-end FASTQ reads were first preprocessed on a by-sample basis using the ‘cellranger count’ command from 10× Genomics’ Cell Ranger v.6.0.1 for alignment against the GRCh38 human reference v.2020-A (‘refdata-gex-GRCh38-2020-A’). To avoid a batch effect introduced by sequencing depth, the ‘cellranger aggr’ command was used to subsample from each sample so that all samples had the same effective sequencing depth, which was measured in terms of the number of reads confidently mapped to the transcriptome or assigned to the feature IDs per cell. Gene annotation on human reference chromosomes and scaffolds in Gene Transfer Format (‘gencode.v32.primary_assembly.annotation.gtf’) was downloaded (on 2 June 2021) from GENCODE v.3247, from which a biotype (‘gene_type’) was extracted for each feature. Quality control was performed as follows on the aggregate gene expression matrix consisting of 432,713 cells and 36,601 features using SCANPY v.1.7.248 and Python v.3.8.8. (1) To remove presumably lysed cells, cells with mitochondrial content greater than 12.5% of all transcripts were removed. (2) To remove likely doublets, cells with more than 8,000 features or 80,000 total UMIs were removed. (3) To remove cells with no detectable expression of common endogenous genes, cells with no transcript for any of the 34 housekeeping genes were removed. (4) The feature matrix was subset, based on their biotypes, to protein-coding, immunoglobulin, and T cell receptor genes that were expressed in at least 0.1% of the cells in any sample. The resultant feature matrix contained 15,842 genes. (5) Cells with detectable expression of fewer than 200 genes were removed. After quality control, there were a total of 383,708 cells from 56 single-cell samples (Extended Data Table 5).
Single-cell gene expression analysis
Single-cell gene expression analysis was performed in SCANPY v.1.7.248. UMI counts measuring gene expression were log-normalized. The top 2,500 highly variable genes (HVGs) were identified using the ‘scanpy.pp.highly_variable_genes’ function with the ‘seurat_v3’ method, from which immunoglobulin and T cell receptor genes were removed. The data were scaled and centred, and principal component analysis (PCA) was performed based on HVG expression. PCA-guided neighborhood graphs embedded in uniform manifold approximation and projection (UMAP) were generated using the top 20 principal components via the ‘scanpy.pp.neighbors’ and ‘scanpy.tl.umap’ functions.
Overall clusters (Extended Data Table 3, top) were identified using Leiden graph-clustering via the ‘scanpy.tl.leiden’ function with resolution 0.23 (Extended Data Fig. 2b). UMAPs were faceted by batch, by participant, and by participant followed by sample; and inspected for convergence across batches, participants, and samples within participants, to assess whether there was a need for integration (Extended Data Fig. 2b). Cluster identities were assigned by examining the expression of a set of marker genes for different cell types (Extended Data Fig. 2c): MS4A1, CD19 and CD79A for B cells; CD3D, CD3E, CD3G, IL7R and CD4 or CD8A for CD4+ or CD8+ T cells, respectively; GZMB, GNLY, NKG7 and NCAM1 for NK cells; CD14, LYZ, CST3 and MS4A7 for monocytes; IL3RA and CLEC4C for plasmacytoid dendritic cells (pDCs); and FDCSP, CXCL1415 and FCAMR16 for FDCs. One group of 27 cells labelled ‘B and T’ was excluded. To remove potential contamination by platelets, 73 cells with a log-normalized expression value of >2.5 for PPBP were removed. All 644 cells from the FDC cluster were confirmed to have originated from FNA samples instead of blood.
Cells from the overall B cell cluster (Extended Data Table 3, bottom) were further clustered to identify B cell subsets using Leiden graph-clustering via the ‘scanpy.tl.leiden’ function with resolution 0.18 (Extended Data Fig. 2d). Cluster identities were assigned by examining the expression of a set of marker genes for different B cell subsets (Extended Data Fig. 2e) along with the availability of BCRs. The following marker genes were examined: BCL6, RGS13, MEF2B, STMN1, ELL3 and SERPINA9 for GC B cells; XBP1, IRF4, SEC11C, FKBP11, JCHAIN and PRDM1 for plasmablasts and LNPCs; TCL1A, IL4R, CCR7, IGHM, and IGHD for naive B cells; and TNFRSF13B, CD27 and CD24 for MBCs. Although one group clustered with B cells during overall clustering, it was labelled ‘B and T’ as its cells tended to have both BCRs and relatively high expression levels of CD2 and CD3E; and was subsequently excluded from the final B cell clustering. Eighteen cells that were found in the GC B cell cluster but came from blood samples were labelled ‘PB-like’13. Two hundred and twenty-three cells that were found in the plasmablast cluster but came from FNA samples were re-assigned as LNPCs. Forty cells that were found in the LNPC cluster but came from blood samples were re-assigned as plasmablasts. Heavy chain SHM frequency and isotype usage of the B cell subsets were assessed for consistency with expected values to further confirm their assigned identities.
Selection of single-cell BCRs from GC B cell or LNPC clusters for expression
Single-cell gene expression analysis was performed using lymph node samples up to and including week 15 on a by-participant basis. Clonal inference was performed based on paired heavy and light chains from the same samples. From every clone with a clone size of more than 3 cells that contained cells from the GC B cell and/or LNPC clusters, one GC B cell or LNPC was selected. For selection, where a clone spanned both the GC B cell and LNPC compartments, and/or multiple time points, a compartment and a timepoint were first randomly selected. Within that clone, the cell with the highest heavy chain UMI count was then selected, breaking ties based on IGHV SHM frequency. In all selected cells, native pairing was preserved.
Selection of BCRs from S-specific BMPC clones for expression
From each heavy chain-based S-specific clone containing both plasmablasts and BMPCs, where possible, one plasmablast heavy chain was selected, and, together with all BMPC heavy chains, were paired with the same light chain for expression. For the plasmablast heavy chain, if single-cell paired plasmablasts were available, the single-cell paired plasmablast whose IGHV mutation frequency was closest to the median mutation frequency of other single-cell paired plasmablasts in the same clone (breaking ties by UMI count), and whose light chain V gene, J gene, and CDR3 length (VJL) combination was consistent with the clonal majority, was used as the source. The natively paired light chain of the plasmablast from which the heavy chain was selected was used. In clones in which two plasmablasts had inconsistent light chain VJL combinations, both plasmablasts were used. Clones in which there was light chain uncertainty due to more than two plasmablasts or due to LNPCs were generally excluded.
Curation of selected BCRs for expression
The selected BCRs were curated prior to synthesis. First, artificial gaps introduced under the IMGT unique numbering system49 were removed from the IMGT-aligned observed V(D)J sequences. IMGT gaps were identified as positions containing in-frame triplet dots (‘…’) in the IMGT-aligned germline sequences. Second, any non-informative (non-A/T/G/C, such as N or -) positions in the observed sequences, with the exception of potential in-frame indels, were patched by the nucleotides at their corresponding germline positions. Third, if applicable, the 3′ end of the observed sequences were trimmed so that the total nucleotide length would be a multiple of 3. Finally, potential in-frame indels were manually reviewed. For a given potential in-frame indel from a selected cell, its presence or lack thereof in the unselected cells from the same clone was considered. Barring strong indications that an in-frame indel was due to sequencing error rather than the incapability of the IMGT unique numbering system of capturing it, the in-frame indels were generally included in the final curated sequences.
Transfection for recombinant monoclonal antibodies and Fab production
Selected pairs of heavy and light chain sequences were synthesized by GenScript and sequentially cloned into IgG1, Igκ/λ and Fab expression vectors. Heavy and light chain plasmids were co-transfected into Expi293F cells (Thermo Fisher Scientific) for recombinant monoclonal antibody production, followed by purification with protein A agarose resin (GoldBio). Expi293F cells were cultured in Expi293 Expression Medium (Gibco) according to the manufacturer’s protocol.
GFP-reduction neutralization test
Serial dilutions of each monoclonal antibody diluted in DMEM were incubated with 102 plaque-forming unit (PFU) of VSV-SARS-CoV-2 D614G for 1 h at 37 °C. Antibody-virus complexes were added to Vero cell monolayers in 96-well plates and incubated at 37 °C for 7.5 h. Cells were fixed at room temperature in 2% formaldehyde (Millipore Sigma) containing 10 μg ml−1 of Hoechst 33342 nuclear stain (Invitrogen) for 45 min at room temperature. Fixative was replaced with PBS prior to imaging. Images were acquired using an IN Cell 2000 Analyzer automated microscope (GE Healthcare) in both the DAPI and FITC channels to visualize nuclei and infected cells. Images were analysed using the Multi Target Analysis Module of the IN Cell Analyzer 1000 Workstation Software (GE Healthcare). GFP-positive cells were identified using the top-hat segmentation method and subsequently counted within the IN Cell workstation software. The initial dilution of monoclonal antibody started at 25 μg ml−1 and was threefold serially diluted in 96-well plate over 8 dilutions.
Affinity analysis by BLI
We used the Octet Red instrument (ForteBio) with shaking at 1,000 rpm. The kinetic analysis using Octet SA biosensors (Sartorius) was performed as follows: (1) baseline: 120 s immersion in buffer (10 mM HEPES and 1% BSA); (2) loading: 130 s immersion in solution with 10 μg ml−1 biotinylated SARS-CoV-2 S Avitag; (3) baseline: 120 s immersion in buffer; (4) association: 300 s immersion in solution with serially diluted recombinant Fab; (5) dissociation: 600 s immersion in buffer. The BLI signal was recorded and analysed using BIAevaluation Software (Biacore). The 1:1 binding model with a drifting baseline was employed for the equilibrium dissociation constant (KD).
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this paper.
Data availability
Raw sequencing data and transcriptomics count matrix are deposited at the Sequence Read Archive (PRJNA777934) and Gene Expression Omnibus (PRJNA777934). Processed transcriptomics and BCR data are deposited at Zenodo (https://doi.org/10.5281/zenodo.5895181). Previously reported bulk-sequenced BCR data used in this study were deposited at the Sequence Read Archive under PRJNA731610 and PRJNA741267, and at https://doi.org/10.5281/zenodo.5042252 and https://doi.org/10.5281/zenodo.5040099.
References
Victora, G. D. & Nussenzweig, M. C. Germinal centers. Annu. Rev. Immunol. 30, 429–457 (2012).
Cyster, J. G. & Allen, C. D. C. B cell responses: cell interaction dynamics and decisions. Cell 177, 524–540 (2019).
Radbruch, A. et al. Competence and competition: the challenge of becoming a long-lived plasma cell. Nat. Rev. Immunol. 6, 741–750 (2006).
Slifka, M. K., Antia, R., Whitmire, J. K. & Ahmed, R. Humoral immunity due to long-lived plasma cells. Immunity 8, 363–372 (1998).
Tarlinton, D., Radbruch, A., Hiepe, F. & Dörner, T. Plasma cell differentiation and survival. Curr. Opin. Immunol. 20, 162–169 (2008).
Turner, J. S. et al. SARS-CoV-2 mRNA vaccines induce persistent human germinal centre responses. Nature 596, 109–113 (2021).
Mudd, P. A. et al. SARS-CoV-2 mRNA vaccination elicits a robust and persistent T follicular helper cell response in humans. Cell 185, 603–613.e15 (2021).
Laidlaw, B. J. & Ellebedy, A. H. The germinal centre B cell response to SARS-CoV-2. Nat. Rev. Immunol. 22, 7–18 (2021).
Goel, R. R. et al. mRNA vaccines induce durable immune memory to SARS-CoV-2 and variants of concern. Science 374, abm0829 (2021).
Cho, A. et al. Anti-SARS-CoV-2 receptor binding domain antibody evolution after mRNA vaccination. Nature 600, 517–522 (2021).
Chen, Y. et al. Differential antibody dynamics to SARS-CoV-2 infection and vaccination. Preprint at https://doi.org/10.1101/2021.09.09.459504 (2021).
Pape, K. A. et al. High-affinity memory B cells induced by SARS-CoV-2 infection produce more plasmablasts and atypical memory B cells than those primed by mRNA vaccines. Cell Rep. 37, 109823 (2021).
Turner, J. S. et al. Human germinal centres engage memory and naive B cells after influenza vaccination. Nature 586, 127–132 (2020).
King, H. W. et al. Single-cell analysis of human B cell maturation predicts how antibody class switching shapes selection dynamics. Sci. Immunol. 6, eabe6291 (2021).
Haebe, S. et al. Single-cell analysis can define distinct evolution of tumor sites in follicular lymphoma. Blood 137, 2869–2880 (2021).
Mourcin, F. et al. Follicular lymphoma triggers phenotypic and functional remodeling of the human lymphoid stromal cell landscape. Immunity 54, 1901 (2021).
Schmitz, A. J. et al. A vaccine-induced public antibody protects against SARS-CoV-2 and emerging variants. Immunity 54, 2159–2166.e2156 (2021).
Hoehn, K. B., Lunter, G. & Pybus, O. G. A phylogenetic codon substitution model for antibody lineages. Genetics 206, 417–427 (2017).
Liu, Z. et al. Identification of SARS-CoV-2 spike mutations that attenuate monoclonal and serum antibody neutralization. Cell Host Microbe 29, 477–488.e474 (2021).
Elsner, R. A. & Shlomchik, M. J. Germinal center and extrafollicular B cell responses in vaccination, immunity, and autoimmunity. Immunity 53, 1136–1150 (2020).
Turner, J. S. et al. SARS-CoV-2 infection induces long-lived bone marrow plasma cells in humans. Nature 595, 421–425 (2021).
Tong, P. et al. Memory B cell repertoire for recognition of evolving SARS-CoV-2 spike. Cell 184, 4969–4980.e4915 (2021).
Sokal, A. et al. mRNA vaccination of naive and COVID-19-recovered individuals elicits potent memory B cells that recognize SARS-CoV-2 variants. Immunity 54, 2893–2907.e5 (2021).
Lucas, C. et al. Impact of circulating SARS-CoV-2 variants on mRNA vaccine-induced immunity. Nature 600, 523–529 (2021).
Smith, K. G. C. The extent of affinity maturation differs between the memory and antibody-forming cell compartments in the primary immune response. EMBO J. 16, 2996–3006 (1997).
Weisel, F. J., Zuccarino-Catania, G. V., Chikina, M. & Shlomchik, M. J. A temporal switch in the germinal center determines differential output of memory B and plasma cells. Immunity 44, 116–130 (2016).
Purtha, W. E., Tedder, T. F., Johnson, S., Bhattacharya, D. & Diamond, M. S. Memory B cells, but not long-lived plasma cells, possess antigen specificities for viral escape mutants. J. Exp. Med. 208, 2599–2606 (2011).
Pape, K. A., Taylor, J. J., Maul, R. W., Gearhart, P. J. & Jenkins, M. K. Different B cell populations mediate early and late memory during an endogenous immune response. Science 331, 1203–1207 (2011).
Stadlbauer, D. et al. SARS‐CoV‐2 seroconversion in humans: a detailed protocol for a serological assay, antigen production, and test setup. Curr. Protoc. Microbiol. 57, e100 (2020).
Fairhead, M. & Howarth, M. Site-specific biotinylation of purified proteins using BirA. Methods Mol. Biol. 1266, 171–184 (2015).
Davis, C. W. et al. Longitudinal analysis of the human B cell response to ebola virus infection. Cell 177, 1566–1582.e1517 (2019).
Vander Heiden, J. A. et al. pRESTO: a toolkit for processing high-throughput sequencing raw reads of lymphocyte receptor repertoires. Bioinformatics 30, 1930–1932 (2014).
Ye, J., Ma, N., Madden, T. L. & Ostell, J. M. IgBLAST: an immunoglobulin variable domain sequence analysis tool. Nucleic Acids Res. 41, W34–W40 (2013).
Brochet, X., Lefranc, M. P. & Giudicelli, V. IMGT/V-QUEST: the highly customized and integrated system for IG and TR standardized V-J and V-D-J sequence analysis. Nucleic Acids Res. 36, W503–W508 (2008).
Gupta, N. T. et al. Change-O: a toolkit for analyzing large-scale B cell immunoglobulin repertoire sequencing data: Table 1. Bioinformatics 31, 3356–3358 (2015).
Gadala-Maria, D., Yaari, G., Uduman, M. & Kleinstein, S. H. Automated analysis of high-throughput B-cell sequencing data reveals a high frequency of novel immunoglobulin V gene segment alleles. Proc. Natl Acad. Sci. USA 112, E862–E870 (2015).
Gupta, N. T. et al. Hierarchical clustering can identify B cell clones with high confidence in Ig repertoire sequencing data. J. Immunol. 198, 2489–2499 (2017).
Zhou, J. Q. & Kleinstein, S. H. Cutting edge: Ig H chains are sufficient to determine most B cell clonal relationships. J. Immunol. 203, 1687–1692 (2019).
Müllner, D. fastcluster: fast hierarchical, agglomerative clustering routines for R and Python. J. Stat. Softw. 53, 1–18 (2013).
Wickham, H. ggplot2: Elegant Graphics for Data Analysis (Springer, 2016).
Gu, Z., Gu, L., Eils, R., Schlesner, M. & Brors, B. circlize implements and enhances circular visualization in R. Bioinformatics 30, 2811–2812 (2014).
Hoehn, K. B. et al. Repertoire-wide phylogenetic models of B cell molecular evolution reveal evolutionary signatures of aging and vaccination. Proc. Natl Acad. Sci. USA 116, 22664–22672 (2019).
Yu, G., Smith, D. K., Zhu, H., Guan, Y. & Lam, T. T. Y. ggtree: an r package for visualization and annotation of phylogenetic trees with their covariates and other associated data. Methods Ecol. Evol. 8, 28–36 (2017).
Hounkpe, B. W., Chenou, F., Franciele, & Erich, HRT Atlas v1.0 database: redefining human and mouse housekeeping genes and candidate reference transcripts by mining massive RNA-seq datasets. Nucleic Acids Res. 49, D947–D955 (2021).
Eisenberg, E. & Levanon, E. Y. Human housekeeping genes, revisited. Trends Genet. 29, 569–574 (2013).
Valente, V. et al. Selection of suitable housekeeping genes for expression analysis in glioblastoma using quantitative RT–PCR. BMC Mol. Biol. 10, 17 (2009).
Frankish, A. et al. GENCODE reference annotation for the human and mouse genomes. Nucleic Acids Res. 47, D766–D773 (2019).
Wolf, F. A., Angerer, P. & Theis, F. J. SCANPY: large-scale single-cell gene expression data analysis. Genome Biol. 19, 15 (2018).
Lefranc, M.-P. et al. IMGT unique numbering for immunoglobulin and T cell receptor variable domains and Ig superfamily V-like domains. Dev. Comp. Immunol. 27, 55–77 (2003).
Acknowledgements
We thank the study participants for providing these specimens. We thank B. J. Laidlaw for critical reading of the manuscript and C. A. Nelson for help with the binding affinity analyses. The Ellebedy laboratory was supported by National Institute of Allergy and Infectious Diseases (NIAID) grants U01AI141990 and 1U01AI150747, NIAID Centers of Excellence for Influenza Research and Surveillance contract HHSN272201400006C and HHSN272201400008C, and NIAID Collaborative Influenza Vaccine Innovation Centers contract 75N93019C00051. W.K. was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2021R1A6A3A03041509). J.S.T. was supported by NIAID 5T32CA009547. This study used samples obtained from the Washington University School of Medicine’s COVID-19 biorepository supported by the NIH/National Center for Advancing Translational Sciences, grant number UL1 TR002345. The content of this manuscript is solely the responsibility of the authors and does not necessarily represent the official view of NIAID or NIH. The WU353 and WU368 studies were reviewed and approved by the Washington University Institutional Review Board (approval numbers 202003186 and 202012081, respectively).
Author information
Authors and Affiliations
Contributions
A.H.E. conceived and designed the study. A.H., M.K.K., L.P.-R., P.A.M., I.P., J.A.O. and R.M.P. wrote and maintained the IRB protocol, recruited, and phlebotomized participants, coordinated sample collection, and analysed clinical data. W.K., E.K. and J.S.T. processed specimens. W.K., E.K., W.B.A. and J.S.T. performed ELISA and ELISpot. W.K., S.C.H., A. J. Schmitz, T.L., M.T. and W.B.A. generated and characterized monoclonal antibodies. W.K. and A. J. Sturtz prepared libraries for scRNA sequencing. A. J. Schmitz performed RNA extractions and library preparation for bulk BCR sequencing. J.Q.Z. analysed scRNA sequencing and bulk BCR sequencing data. A. J. Schmitz expressed SARS-CoV-2 S proteins. J.S.T. sorted cells and collected and analysed the flow cytometry data. T.S. and W.D.M. performed FNA. W.D.M. and S.A.T. supervised lymph node evaluation prior to FNA and specimen collection and evaluated lymph node ultrasound data. Z.L. and S.P.J.W. performed and analysed the in vitro neutralization assay. W.K., J.Q.Z., J.S.T. and A.H.E. analysed the data. A.H.E. supervised experiments and obtained funding. W.K., J.Q.Z., P.A.M., J.S.T. and A.H.E. wrote the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The Ellebedy laboratory received funding under sponsored research agreements from Emergent BioSolutions and from AbbVie. J.S.T. is a consultant for Gerson Lehrman Group.
Peer review
Peer review information
Nature thanks the anonymous reviewers for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Persistence of humoral immune responses to SARS-CoV-2 mRNA vaccination.
a, Flow cytometry gating strategies for GC B cells (Fig. 1b) and LNPCs (defined as CD19+ CD3- IgDlow CD20low CD38+ BLIMP1+ CD71+ live singlet lymphocytes) in the lymph node. b, Kinetics of total (left) and S-specific LNPCs (right) as gated in a. c, Frequencies of BMPCs secreting IgA antibodies specific for the indicated antigens 29 weeks after immunization. Symbols represent one sample in b (n = 15) and c (n = 11). d, e, Plasma antibody titers against SARS-CoV-2 S measured by ELISA in participants without (red, n = 29) and with (black, n = 9) a history of SARS-CoV-2 infection in SARS-CoV-2 vaccinated (left, center) and unvaccinated (right, n = 48) participants 29 weeks after the first vaccine dose or symptom onset (d) and in vaccinated participants (red, n = 29; black, n = 9) over time (e). P values were determined by Kruskal-Wallis test followed by Dunn’s multiple comparison test between unvaccinated and both vaccinated groups in d. Horizontal lines indicate median values and geometric mean, respectively, in c and d. Dotted lines indicate detection limit in c, d and e. f, Flow cytometry gating strategies for MBCs (CD19+ CD3- IgDlow CD20+ CD38- live singlet lymphocytes) and S-binding MBCs (Fig. 1g) in blood.
Extended Data Fig. 2 Identification of SARS-CoV-2 S-binding B cell clones in the lymph node.
a, Flow cytometry gating strategies for sorting PBs (defined as CD19+ CD3- IgDlow CD20low CD38+ CD71+ live singlet lymphocytes) from blood. b, d UMAPs showing scRNA-seq transcriptional clusters of total cells (b) and of B cells (d) from PBs sorted from blood and FNA of draining axillary lymph nodes combined. c, e, Dot plots for the marker genes used for identifying annotated clusters. f, Heatmap of paired IGHV and IGHJ gene usage in S-binding clones. Color indicates the number of participants in which clones using a combination of IGHV and IGHJ genes were found. g, Flow cytometry gating strategies for sorting GC B cells (CD19+ CD4- IgDlow CD20+ CD38int CXCR5high CD71+ live singlet lymphocytes) and LNPCs (CD19+ CD4- IgDlow CD20low CD38+ CXCR5low CD71+ live singlet lymphocytes) from FNAs. h, SARS-CoV-2 S-binding clones visualized in red on UMAP of B cell clusters. Percentages are of S-binding clones within GC B cells (blue), LNPCs (green), PBs (red), MBCs (pink) or naive B cells (yellow). Total numbers of cells are at the bottom right corner.
Extended Data Fig. 3 Maturation of SARS-CoV-2 S-binding B cells in the lymph node.
a, Circos diagrams showing clonal overlap between S-binding GC B cells at indicated time points. Purple and grey chords correspond to, respectively, clones spanning both 29 weeks post-vaccination and other time points, and clones spanning one or more of 4, 7 and 15 weeks post-vaccination. Percentages are of GC B cell clones related to GC B cells detected at 29 weeks post-vaccination. b, Circos diagrams showing clonal overlap between S-binding MBCs in blood 29 weeks post-vaccination and GC B cells at indicated time points. Purple and grey chords correspond to, respectively, clones spanning both the MBC and GC B cell compartments, and clones spanning only the GC B cell compartment. Percentages are of GC B cell clones overlapping with MBCs in blood 29 weeks post-vaccination. Arc length corresponds to the number of BCR sequences and chord with corresponds to clone size in a and b. c, Comparison of IGHV nucleotide mutation frequency of SARS-CoV-2 S-binding GC B cells in each participant at the indicated time points. Horizontal lines represent median values. Cell numbers are presented on the top of each data set. d, Comparison of IGHV region nucleotide mutation frequencies between clonally related, SARS-CoV-2 S-binding GC B cells and MBCs (n = 33) detected at 29 weeks post-vaccination. Each dot represents the median SHM frequency of a clone within the indicated compartment. Median values are presented on the top of each data set. P value was determined by a paired two-sided non-parametric Mann-Whitney test. e, Percentages of GC B cells expressing BCRs of isotype IgG (blue), IgA (red), IgM (green) or IgD (pink) at the early (E) or the late (L) time point. The early and late time points represent, respectively, 4, 5 or 7 weeks, and 15 or 29 weeks after immunization. Cell numbers are at the top.
Extended Data Fig. 4 Evolution of B cell clones induced by SARS-CoV-2 vaccination.
a, a, Comparison of IGHV nucleotide mutation frequency of PBs (n = 2735), GC B cells (n = 139322), LNPCs (n = 82350), MBCs (n = 341) and BMPCs (n = 47). Horizontal lines represent median values. P values were determined by Kruskal-Wallis test followed by Dunn’s multiple comparison test. b, Phylogenetic trees of neutralizing clones showing inferred evolutionary relationships between PBs (squares), LNPCs (triangles) and BMPCs (diamonds). Horizontal branch length represents the expected number of substitutions per codon in V-region genes, corresponding to the scale bar. Clone IDs are displayed near the root of the trees. Asterisks denote neutralizing mAbs. c, Kinetic curves of BLI signal for clonally related, PB- and BMPC-derived Fabs interacting with immobilized SARS-CoV-2 S. Clone IDs, Fab IDs and cell types are presented on the top of each data set. Asterisks denote neutralizing clones. d, Equilibrium dissociation constant (KD) of Fabs (n = 24) interacting with immobilized SARS-CoV-2 S measured by biolayer interferometry (BLI). Red and black dots indicate KD values of clonally related, PB- and BMPC-derived Fabs, respectively. P value was determined by Wilcoxon matched-pair signed rank test. e, Neutralization curves of VSV-SARS-CoV-2 D614G with BMPC-derived mAbs. Colored and grey lines represent neutralizing and non-neutralizing clones, respectively. Neutralizing clone IDs are indicated on each curve. ns > 0.9999, ****P < 0.0001.
Supplementary information
Rights and permissions
About this article

Cite this article
Kim, W., Zhou, J.Q., Horvath, S.C. et al. Germinal centre-driven maturation of B cell response to mRNA vaccination. Nature 604, 141–145 (2022). https://doi.org/10.1038/s41586-022-04527-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-022-04527-1
This article is cited by
-
New insights into the ontogeny, diversity, maturation and survival of long-lived plasma cells
Nature Reviews Immunology (2024)
-
MVA-based vaccine candidates encoding the native or prefusion-stabilized SARS-CoV-2 spike reveal differential immunogenicity in humans
npj Vaccines (2024)
-
Memory B cells
Nature Reviews Immunology (2024)
-
Frailty impacts immune responses to Moderna COVID-19 mRNA vaccine in older adults
Immunity & Ageing (2023)
-
Humoral immunity for durable control of SARS-CoV-2 and its variants
Inflammation and Regeneration (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
